

model.embedding.weight.data = TEXT.vocab.vectors텍스트 데이터 분석

토큰화
데모에 사용할 영화 후기
The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic shit in this movie and he is definitely not under-powered anymore. Thor is unleashed in this, I love that.
텍스트를 문자로 변환
코드
thor_review = "The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic shit in this movie and he is definitely not under-powered anymore. Thor is unleashed in this, I love that."
print(list(thor_review))출력
['T', 'h', 'e', ' ', 'a', 'c', 't', 'i', 'o', 'n', ' ', 's', 'c', 'e', 'n', 'e', 's', ' ', 'w', 'e', 'r', 'e', ' ', 't', 'o', 'p', ' ', 'n', 'o', 't', 'c', 'h', ' ', 'i', 'n', ' ', 't', 'h', 'i', 's', ' ', 'm', 'o', 'v', 'i', 'e', '.', ' ', 'T', 'h', 'o', 'r', ' ', 'h', 'a', 's', ' ', 'n', 'e', 'v', 'e', 'r', ' ', 'b', 'e', 'e', 'n', ' ', 't', 'h', 'i', 's', ' ', 'e', 'p', 'i', 'c', ' ', 'i', 'n', ' ', 't', 'h', 'e', ' ', 'M', 'C', 'U', '.', ' ', 'H', 'e', ' ', 'd', 'o', 'e', 's', ' ', 's', 'o', 'm', 'e', ' ', 'p', 'r', 'e', 't', 't', 'y', ' ', 'e', 'p', 'i', 'c', ' ', 's', 'h', 'i', 't', ' ', 'i', 'n', ' ', 't', 'h', 'i', 's', ' ', 'm', 'o', 'v', 'i', 'e', ' ', 'a', 'n', 'd', ' ', 'h', 'e', ' ', 'i', 's', ' ', 'd', 'e', 'f', 'i', 'n', 'i', 't', 'e', 'l', 'y', ' ', 'n', 'o', 't', ' ', 'u', 'n', 'd', 'e', 'r', '-', 'p', 'o', 'w', 'e', 'r', 'e', 'd', ' ', 'a', 'n', 'y', 'm', 'o', 'r', 'e', '.', ' ', 'T', 'h', 'o', 'r', ' ', 'i', 's', ' ', 'u', 'n', 'l', 'e', 'a', 's', 'h', 'e', 'd', ' ', 'i', 'n', ' ', 't', 'h', 'i', 's', ',', ' ', 'I', ' ', 'l', 'o', 'v', 'e', ' ', 't', 'h', 'a', 't', '.']
텍스트를 단어로 변환
코드
print(thor_review.split())출력
['The', 'action', 'scenes', 'were', 'top', 'notch', 'in', 'this', 'movie.', 'Thor', 'has', 'never', 'been', 'this', 'epic', 'in', 'the', 'MCU.', 'He', 'does', 'some', 'pretty', 'epic', 'shit', 'in', 'this', 'movie', 'and', 'he', 'is', 'definitely', 'not', 'under-powered', 'anymore.', 'Thor', 'is', 'unleashed', 'in', 'this,', 'I', 'love', 'that.']
N-그램 표현
코드
from nltk import ngrams
thor_review = "The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic shit in this movie and he is definitely not under-powered anymore. Thor is unleashed in this, I love that."
print(list(ngrams(thor_review.split(), 2)))출력
[('The', 'action'), ('action', 'scenes'), ('scenes', 'were'), ('were', 'top'), ('top', 'notch'), ('notch', 'in'), ('in', 'this'), ('this', 'movie.'), ('movie.', 'Thor'), ('Thor', 'has'), ('has', 'never'), ('never', 'been'), ('been', 'this'), ('this', 'epic'), ('epic', 'in'), ('in', 'the'), ('the', 'MCU.'), ('MCU.', 'He'), ('He', 'does'), ('does', 'some'), ('some', 'pretty'), ('pretty', 'epic'), ('epic', 'shit'), ('shit', 'in'), ('in', 'this'), ('this', 'movie'), ('movie', 'and'), ('and', 'he'), ('he', 'is'), ('is', 'definitely'), ('definitely', 'not'), ('not', 'under-powered'), ('under-powered', 'anymore.'), ('anymore.', 'Thor'), ('Thor', 'is'), ('is', 'unleashed'), ('unleashed', 'in'), ('in', 'this,'), ('this,', 'I'), ('I', 'love'), ('love', 'that.')]
코드
print(list(ngrams(thor_review.split(), 3)))출력
[('The', 'action', 'scenes'), ('action', 'scenes', 'were'), ('scenes', 'were', 'top'), ('were', 'top', 'notch'), ('top', 'notch', 'in'), ('notch', 'in', 'this'), ('in', 'this', 'movie.'), ('this', 'movie.', 'Thor'), ('movie.', 'Thor', 'has'), ('Thor', 'has', 'never'), ('has', 'never', 'been'), ('never', 'been', 'this'), ('been', 'this', 'epic'), ('this', 'epic', 'in'), ('epic', 'in', 'the'), ('in', 'the', 'MCU.'), ('the', 'MCU.', 'He'), ('MCU.', 'He', 'does'), ('He', 'does', 'some'), ('does', 'some', 'pretty'), ('some', 'pretty', 'epic'), ('pretty', 'epic', 'shit'), ('epic', 'shit', 'in'), ('shit', 'in', 'this'), ('in', 'this', 'movie'), ('this', 'movie', 'and'), ('movie', 'and', 'he'), ('and', 'he', 'is'), ('he', 'is', 'definitely'), ('is', 'definitely', 'not'), ('definitely', 'not', 'under-powered'), ('not', 'under-powered', 'anymore.'), ('under-powered', 'anymore.', 'Thor'), ('anymore.', 'Thor', 'is'), ('Thor', 'is', 'unleashed'), ('is', 'unleashed', 'in'), ('unleashed', 'in', 'this,'), ('in', 'this,', 'I'), ('this,', 'I', 'love'), ('I', 'love', 'that.')]
벡터화
원-핫 인코딩
An apple a day keeps doctor away said the doctor.
위 문장을 원-핫 인코딩 변환시키면 다음 표 형식과 같이 표현될 수 있다.
| An | 100000000 |
| apple | 010000000 |
| a | 001000000 |
| day | 000100000 |
| keeps | 000010000 |
| doctor | 000001000 |
| away | 000000100 |
| said | 000000010 |
| the | 000000001 |
import numpy as np
class Dictionary(object):
def __init__(self):
self.word2idx = {}
self.idx2word = []
self.length = 0
def add_word(self, word):
if word not in self.idx2word:
self.idx2word.append(word)
self.word2idx[word] = self.length = 1
self.length += 1
return self.word2idx[word]
def __len__(self):
return len(self.idx2word)
def onehot_encoded(self, word):
vec = np.zeros(self.length)
vec[self.word2idx[word]] = 1
return vec코드
thor_review = "The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic shit in this movie and he is definitely not under-powered anymore. Thor is unleashed in this, I love that."
dic = Dictionary()
for tok in thor_review.split():
dic.add_word(tok)
print(dic.word2idx)출력
{'The': 1, 'action': 1, 'scenes': 1, 'were': 1, 'top': 1, 'notch': 1, 'in': 1, 'this': 1, 'movie.': 1, 'Thor': 1, 'has': 1, 'never': 1, 'been': 1, 'epic': 1, 'the': 1, 'MCU.': 1, 'He': 1, 'does': 1, 'some': 1, 'pretty': 1, 'shit': 1, 'movie': 1, 'and': 1, 'he': 1, 'is': 1, 'definitely': 1, 'not': 1, 'under-powered': 1, 'anymore.': 1, 'unleashed': 1, 'this,': 1, 'I': 1, 'love': 1, 'that.': 1}
워드 임베딩

감성 분류기로 워드 임베딩 학습시키기
IMDB 다운로드와 텍스트 토큰화
torchtext 설치를 위해 명령어 콘솔에서 다음 명령을 입력한다.
pip install torchtext
torchtext.data
from torchtext import data
TEXT = data.Field(lower=True, batch_first=True, fix_length=40)
LABEL = data.Field(sequential=False)책에는 위 코드로 안내되어 있지만 다음과 같은 에러가 난다.
Traceback (most recent call last):
File "/root/PycharmProjects/dl_with_pytorch/ch06/imdb_download_and_text_tokenization.py", line 4, in <module>
TEXT = data.Field(lower=True, bacth_first=True, fix_length=40)
AttributeError: module 'torchtext.data' has no attribute 'Field'torchtext 임포트 방법이 바뀌어서 나는 에러로, 다음과 같이 임포트 문을 바꿔야 한다. 참고
from torchtext.legacy import data
TEXT = data.Field(lower=True, batch_first=True, fix_length=40)
LABEL = data.Field(sequential=False)
torchtext.datasets
from torchtext.legacy import data
from torchtext import datasets
# torchtext.data
TEXT = data.Field(lower=True, batch_first=True, fix_length=40)
LABEL = data.Field(sequential=False)
# torchtext.datasets
train, test = datasets.IMDB.splits(TEXT, LABEL)
print('train.fields', train.fields)
print(vars(train[0]))책에서는 위와 같이 안내되어 있지만 다음과 같은 에러가 난다.
Traceback (most recent call last):
File "/root/PycharmProjects/dl_with_pytorch/ch06/imdb_download_and_text_tokenization.py", line 10, in <module>
train, test = datasets.IMDB.splits(TEXT, LABEL)
AttributeError: 'function' object has no attribute 'splits'마찬가지로 torchtext 임포트 방법이 바뀌어서 나는 에러로, 다음과 같이 임포트해야한다.
from torchtext.legacy import data, datasets
# torchtext.data
TEXT = data.Field(lower=True, batch_first=True, fix_length=40)
LABEL = data.Field(sequential=False)
# torchtext.datasets
train, test = datasets.IMDB.splits(TEXT, LABEL)
print('train.fields', train.fields)
print(vars(train[0]))
어휘 구축
TEXT.build_vocab(train, vectors=GloVe(name='6B', dim=300),max_size=10000,min_freq=10)
LABEL.build_vocab(train)다음 코드를 통해 어휘에 포함된 정보와 결과에 접근할 수 있다.
# 정보 접근
print(TEXT.vocab.freqs)
# 결과 접근
print(TEXT.vocab.vectors)
벡터 배치 생성
train_iter, test_iter = data.BucketIterator.splits((train, test), batch_size=64, device=-1,shuffle=True)
train_iter.repeat = False
test_iter.repeat = False# 배치 생성
batch = next(iter(train_iter))
# 배치에 포함된 데이터 확인
print(batch.text)
임베딩으로 네트워크 모델 만들기
class EmbNet(nn.Module):
def __init__(self,emb_size,hidden_size1,hidden_size2=400):
super().__init__()
self.embedding = nn.Embedding(emb_size,hidden_size1)
self.fc1 = nn.Linear(hidden_size2,3)
def forward(self,x):
embeds = self.embedding(x).view(x.size(0),-1)
out = self.fc1(embeds)
return F.log_softmax(out,dim=-1)
모델 학습시키기
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , batch in enumerate(data_loader):
text , target = batch.text , batch.label
if is_cuda:
text,target = text.cuda(),target.cuda()
if phase == 'training':
optimizer.zero_grad()
output = model(text)
loss = F.nll_loss(output,target)
running_loss += F.nll_loss(output,target,size_average=False).data
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct.item()/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}')
return loss,accuracy
train_losses, train_accuracy = [], []
val_losses, val_accuracy = [], []
train_iter.repeat = False
test_iter.repeat = False
for epoch in range(1,10):
epoch_loss, epoch_accuracy = fit(epoch,model,train_iter,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,test_iter,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
사전 학습 워드 임베딩
임베딩 다운로드
from torchtext.vocab import GloVe
TEXT.build_vocab(train,test, vectors=GloVe(name='6B', dim=300),max_size=10000,min_freq=10)
LABEL.build_vocab(train,)코드
print(TEXT.vocab.vectors)출력
tensor([[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0466, 0.2132, -0.0074, ..., 0.0091, -0.2099, 0.0539],
...,
[ 0.3619, 0.1310, -0.0638, ..., 0.0524, -0.0845, -0.6953],
[-0.1303, -0.3711, -0.1305, ..., 0.2463, 0.7618, 0.0235],
[-0.2805, -0.1920, 0.0510, ..., -0.1103, -0.2571, 0.0703]])
모델에 임베딩 로딩하기
model.embedding.weight.data = TEXT.vocab.vectorsclass EmbNet(nn.Module):
def __init__(self,emb_size,hidden_size1,hidden_size2=400):
super().__init__()
self.embedding = nn.Embedding(emb_size,hidden_size1)
self.fc1 = nn.Linear(hidden_size2,3)
def forward(self,x):
embeds = self.embedding(x).view(x.size(0),-1)
out = self.fc1(embeds)
return F.log_softmax(out,dim=-1)
model = EmbNet(len(TEXT.vocab.stoi),300,12000)
임베딩 레이어 가중치 고정
model.embedding.weight.requires_grad = False
optimizer = optim.SGD([ param for param in model.parameters() if param.requires_grad == True], lr=0.001)
RNN

RNN 작동 방식 이해

rnn = RNN(input_size, hidden_size, output_size)
for i in range(len(Thor_review)):
output, hidden = rnn(thor_review[i], hidden)import torch
import torch.nn as nn
from torch.autograd import Variable
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(seld, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return Variable(torch.zeros(1, self.hidden_size))
LSTM
장기 종속성
I am born in Chennai a city in Tamilnadu. Did schooling in different states of India and I speak...
LSTM 네트워크

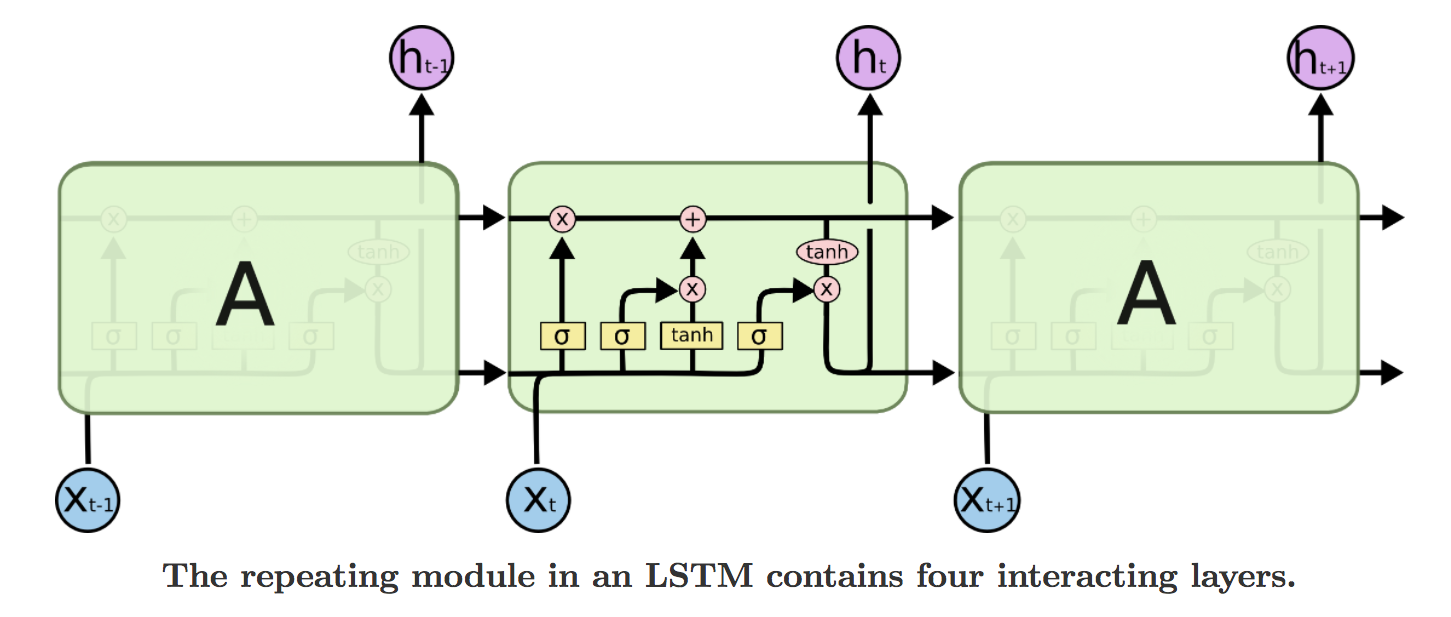
데이터 준비하기
TEXT = data.Field(lower=True, fix_length=200, batch_first=False)
LABEL = data.Field(sequential=False, )
train, test = IMDB.splits(TEXT, LABEL)
TEXT.build_vocab(train, vectors=GloVe(name='6B', dim=300), max_size=10000, min_freq=10)
LABEL.build_vocab(train, )
배치 처리기 생성하기
네트워크 생성하기
train_iter, test_iter = data.BucketIterator.splits((train, test), batch_size=32, device=-1)
train_iter.repeat = False
test_iter.repeat = Falseclass IMDBRnn(nn.Module):
def __init__(self,vocab,hidden_size,n_cat,bs=1,nl=2):
super().__init__()
self.hidden_size = hidden_size
self.bs = bs
self.nl = nl
self.e = nn.Embedding(n_vocab,hidden_size)
self.rnn = nn.LSTM(hidden_size,hidden_size,nl)
self.fc2 = nn.Linear(hidden_size,n_cat)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self,inp):
bs = inp.size()[1]
if bs != self.bs:
self.bs = bs
e_out = self.e(inp)
h0 = c0 = Variable(e_out.data.new(*(self.nl,self.bs,self.hidden_size)).zero_())
rnn_o,_ = self.rnn(e_out,(h0,c0))
rnn_o = rnn_o[-1]
fc = F.dropout(self.fc2(rnn_o),p=0.8)
return self.softmax(fc)
모델 학습시키기
model = IMDBRnn(n_vocab,n_hidden,3,bs=32)
model = model.cuda()
optimizer = optim.Adam(model.parameters(),lr=1e-3)
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , batch in enumerate(data_loader):
text , target = batch.text , batch.label
if is_cuda:
text,target = text.cuda(),target.cuda()
if phase == 'training':
optimizer.zero_grad()
output = model(text)
loss = F.nll_loss(output,target)
running_loss += F.nll_loss(output,target,size_average=False).data
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct.item()/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}')
return loss,accuracy
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,5):
epoch_loss, epoch_accuracy = fit(epoch,model,train_iter,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,test_iter,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
시퀀스 데이터와 CNN
시퀀스 데이터를 위한 1D 컨볼루션 이해

네트워크 만들기
class IMDBCnn(nn.Module):
def __init__(self,vocab,hidden_size,n_cat,bs=1,kernel_size=3,max_len=200):
super().__init__()
self.hidden_size = hidden_size
self.bs = bs
self.e = nn.Embedding(n_vocab,hidden_size)
self.cnn = nn.Conv1d(max_len,hidden_size,kernel_size)
self.avg = nn.AdaptiveAvgPool1d(10)
self.fc = nn.Linear(1000,n_cat)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self,inp):
bs = inp.size()[0]
if bs != self.bs:
self.bs = bs
e_out = self.e(inp)
cnn_o = self.cnn(e_out)
cnn_avg = self.avg(cnn_o)
cnn_avg = cnn_avg.view(self.bs,-1)
fc = F.dropout(self.fc(cnn_avg),p=0.5)
return self.softmax(fc)
모델 학습시키기
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,5):
epoch_loss, epoch_accuracy = fit(epoch,model,train_iter,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,test_iter,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
요약
6장에서는
- 딥러닝으로 텍스트 데이터를 표현하는 다양한 기술
- 미리 학습된 워드 임베딩을 사용하는 방법
- 다른 도메인에서 작업할 때, 미리 학습된 임베딩을 사용하는 방법
- LSTM과 1D 컨볼루션을 사용한 문장 분류기 실습
7장에서는
- 딥러닝 알고리즘을 학습시켜 세련된 이미지와 새로운 이미지를 생성하고, 텍스트를 만드는 기법
'IT 도서 리뷰' 카테고리의 다른 글
| [CS 전공지식 노트] CH1 디자인패턴과 프로그래밍 패러다임 (0) | 2023.05.29 |
|---|---|
| PyTorch로 시작하는 딥러닝 - CH7 생성적 신경망 (0) | 2021.11.14 |
| PyTorch로 시작하는 딥러닝 - CH5 컴퓨터 비전 딥러닝 (0) | 2021.11.11 |
| PyTorch로 시작하는 딥러닝 - CH4 머신 러닝 입문 (0) | 2021.11.11 |
| PyTorch로 시작하는 딥러닝 - CH2 신경망 구성 요소 (0) | 2021.10.29 |