

신경망 첫걸음

MNIST - 데이터 가져오기
CNN모델 구축
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(56180, 500)
self.fc2 = nn.Linear(500,50)
self.fc3 = nn.Linear(50, 2)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = F.relu(self.fc2(x))
x = F.dropout(x,training=self.training)
x = self.fc3(x)
return F.log_softmax(x,dim=1)CONV2D
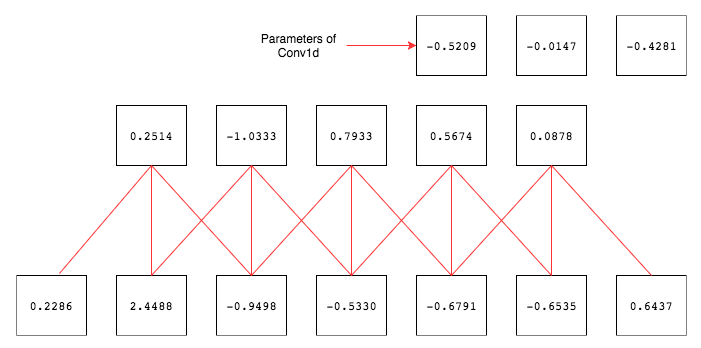
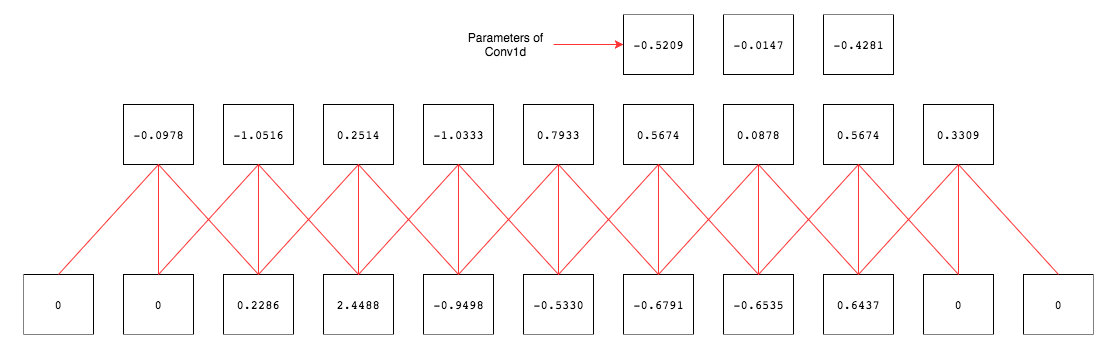
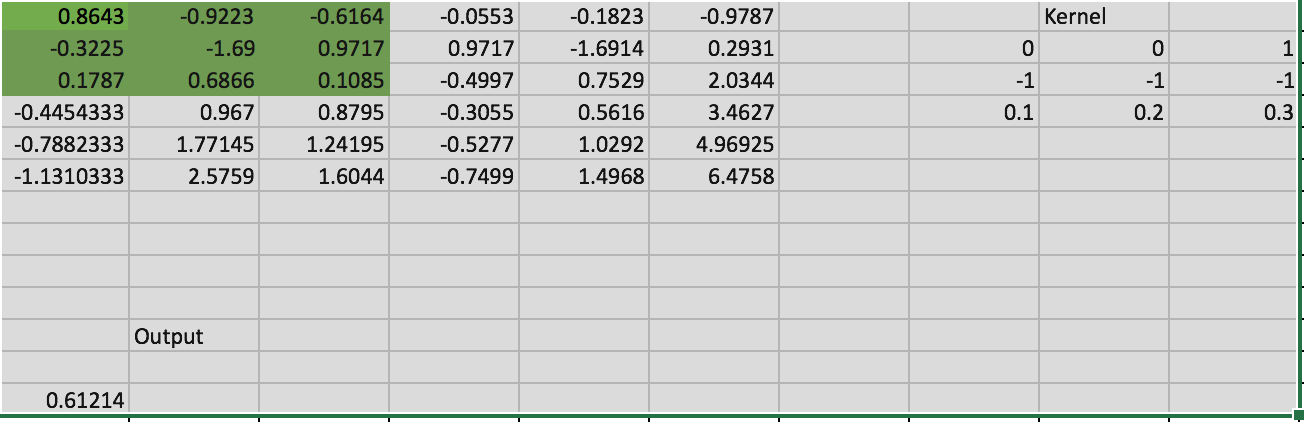
풀링
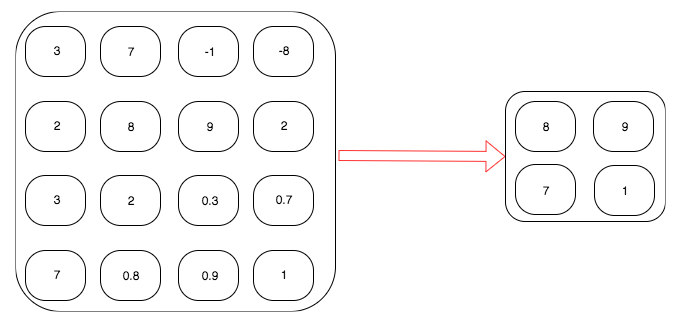
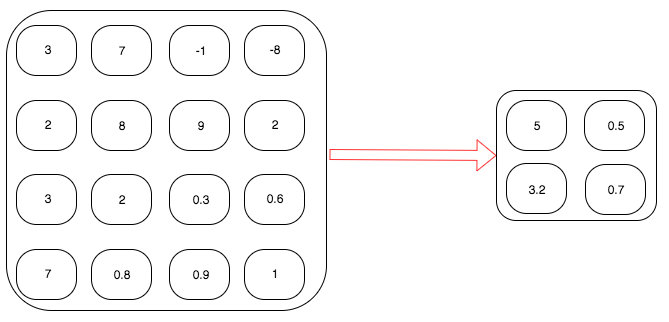
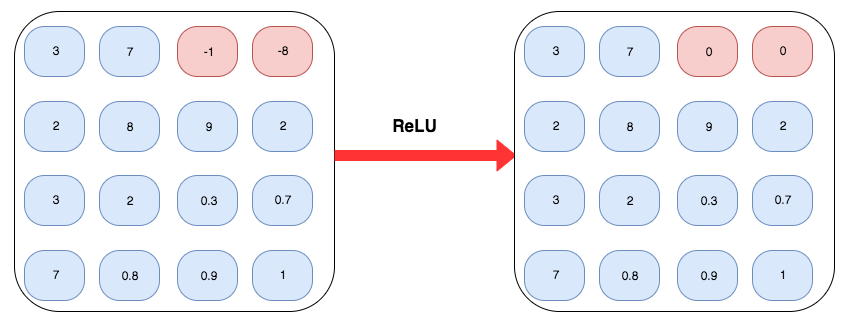
비선형 활성화 레이어 - ReLU
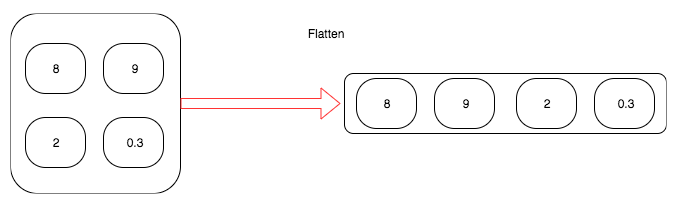
뷰

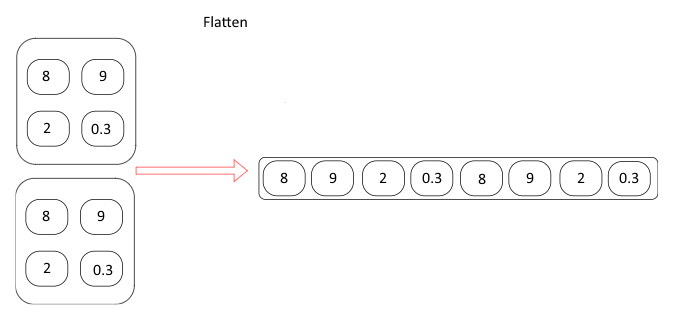
선형 레이어
모델 학습
def fit(epoch,model,data_loader,phase='training',volatile=False):
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output,target)
running_loss += F.nll_loss(output,target,size_average=False).data
preds = output.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct.item()/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{10}.{4}}')
return loss,accuracymodel = Net()
if is_cuda:
model.cuda()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,20):
epoch_loss, epoch_accuracy = fit(epoch,model,train_data_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,valid_data_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)plt.plot(range(1,len(train_losses)+1),train_losses,'bo',label = 'training loss')
plt.plot(range(1,len(val_losses)+1),val_losses,'r',label = 'validation loss')
plt.legend()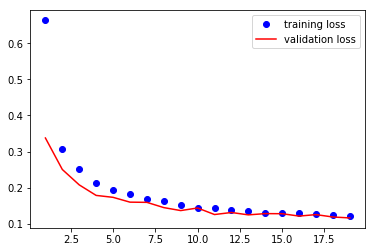
plt.plot(range(1,len(train_accuracy)+1),train_accuracy,'bo',label = 'train accuracy')
plt.plot(range(1,len(val_accuracy)+1),val_accuracy,'r',label = 'val accuracy')
plt.legend()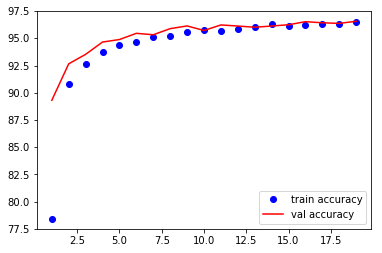
CNN을 이용한 개와 고양이 분류
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(56180, 500)
self.fc2 = nn.Linear(500,50)
self.fc3 = nn.Linear(50, 2)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = F.relu(self.fc2(x))
x = F.dropout(x,training=self.training)
x = self.fc3(x)
return F.log_softmax(x,dim=1)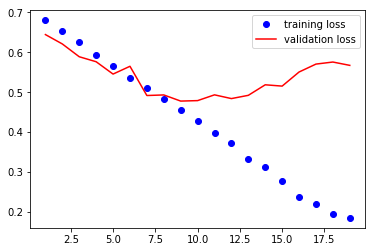
전이 학습을 이용한 개와 고양이 분류
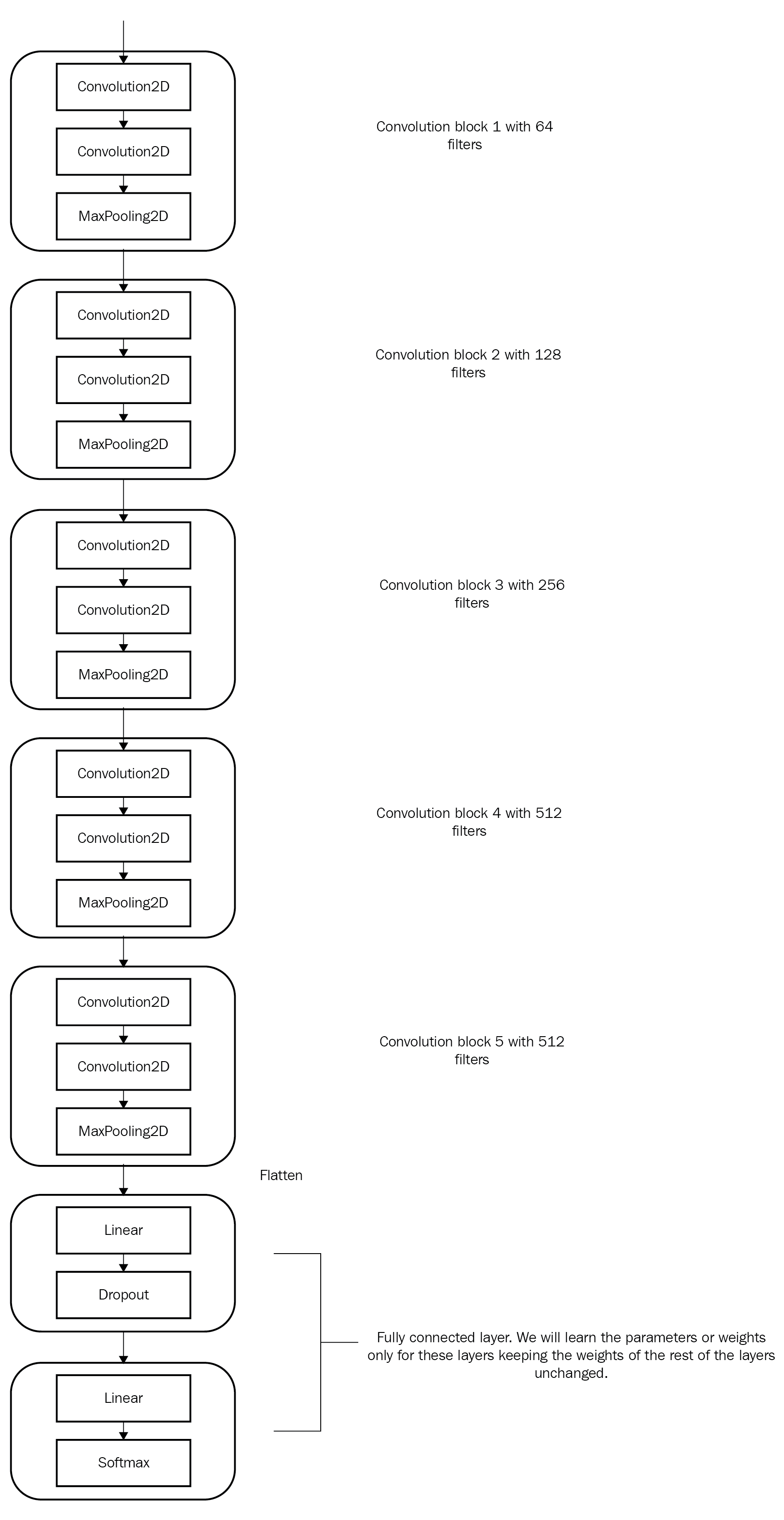
VGG16 모델 생성과 탐색
VGG16 모델을 생성하는 코드는 다음과 같다.
from torchvision import models
vgg = models.vgg16(pretrained=True)다음 코드를 통해 VGG16 모델의 구조를 살펴보자.
print(vgg)아래는 VGG16 모델의 구조이다.
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)VGG16은 순차모델인 features와 classifier로 구성됨을 알 수 있다.
레이어 고정
for param in vgg.features.parameters(): param.requires_grad = False
세부 조정: VGG16
vgg.classifier[6].out_features = 2
optimizer = optim.SGD(vgg.classifier.parameters(),lr=0.0001,momentum=0.5)
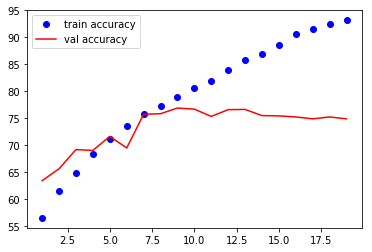
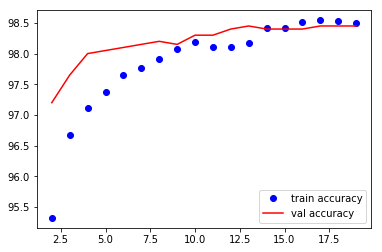
VGG16 모델 학습
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,20):
epoch_loss, epoch_accuracy = fit(epoch,model,train_data_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,valid_data_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)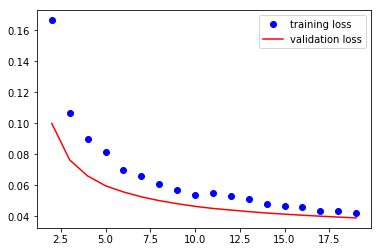
for layer in vgg.classifier.children():
if(type(layer) == nn.Dropout):
layer.p = 0.2
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,3):
epoch_loss, epoch_accuracy = fit(epoch,vgg,train_data_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,vgg,valid_data_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
데이터 증식
train_transform = transforms.Compose([transforms.Resize((224,224))
,transforms.RandomHorizontalFlip()
,transforms.RandomRotation(0.2)
,transforms.ToTensor()
,transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train = ImageFolder('../Chapter03/dogsandcats/train/',train_transform)
valid = ImageFolder('../Chapter03/dogsandcats/valid/',simple_transform)
In [27]:
train_data_loader = DataLoader(train,batch_size=32,num_workers=3,shuffle=True)
valid_data_loader = DataLoader(valid,batch_size=32,num_workers=3,shuffle=True)
In [28]:
%%time
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,3):
epoch_loss, epoch_accuracy = fit(epoch,vgg,train_data_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,vgg,valid_data_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
사전 계산된 컨볼루션 피처 사용
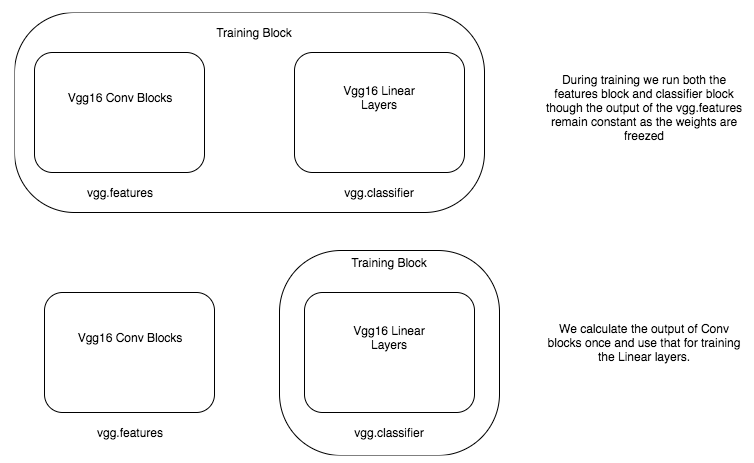
vgg = models.vgg16(pretrained=True)
vgg = vgg.cuda()
features = vgg.features
for param in features.parameters(): param.requires_grad = False
train_data_loader = torch.utils.data.DataLoader(train,batch_size=32,num_workers=3,shuffle=False)
valid_data_loader = torch.utils.data.DataLoader(valid,batch_size=32,num_workers=3,shuffle=False)
def preconvfeat(dataset,model):
conv_features = []
labels_list = []
for data in dataset:
inputs,labels = data
if is_cuda:
inputs , labels = inputs.cuda(),labels.cuda()
inputs , labels = Variable(inputs),Variable(labels)
output = model(inputs)
conv_features.extend(output.data.cpu().numpy())
labels_list.extend(labels.data.cpu().numpy())
conv_features = np.concatenate([[feat] for feat in conv_features])
return (conv_features,labels_list)
conv_feat_train,labels_train = preconvfeat(train_data_loader,features)
conv_feat_val,labels_val = preconvfeat(valid_data_loader,features)class My_dataset(Dataset):
def __init__(self,feat,labels):
self.conv_feat = feat
self.labels = labels
def __len__(self):
return len(self.conv_feat)
def __getitem__(self,idx):
return self.conv_feat[idx],self.labels[idx]
train_feat_dataset = My_dataset(conv_feat_train,labels_train)
val_feat_dataset = My_dataset(conv_feat_val,labels_val)
train_feat_loader = DataLoader(train_feat_dataset,batch_size=64,shuffle=True)
val_feat_loader = DataLoader(val_feat_dataset,batch_size=64,shuffle=True)train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(1,20):
epoch_loss, epoch_accuracy = fit(epoch,model,train_data_loader,phase='training')
val_epoch_loss , val_epoch_accuracy = fit(epoch,model,valid_data_loader,phase='validation')
train_losses.append(epoch_loss)
train_accuracy.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
CNN 학습에 대한 이해
중간 레이어의 출력 시각화
vgg = models.vgg16(pretrained=True).cuda()
class LayerActivations():
features=None
def __init__(self,model,layer_num):
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
def hook_fn(self,module,input,output):
self.features = output.cpu().data.numpy()
def remove(self):
self.hook.remove()
conv_out = LayerActivations(vgg.features,0)
o = vgg(Variable(img.cuda()))
conv_out.remove()
act = conv_out.features다음 고양이 이미지가 입력될 때, 각 레이어가 만드는 활성화 출력을 이미지로 만들어본다.
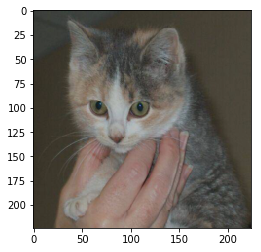
fig = plt.figure(figsize=(20,50))
fig.subplots_adjust(left=0,right=1,bottom=0,top=0.8,hspace=0,wspace=0.2)
for i in range(30):
ax = fig.add_subplot(12,5,i+1,xticks=[],yticks=[])
ax.imshow(act[0][i])

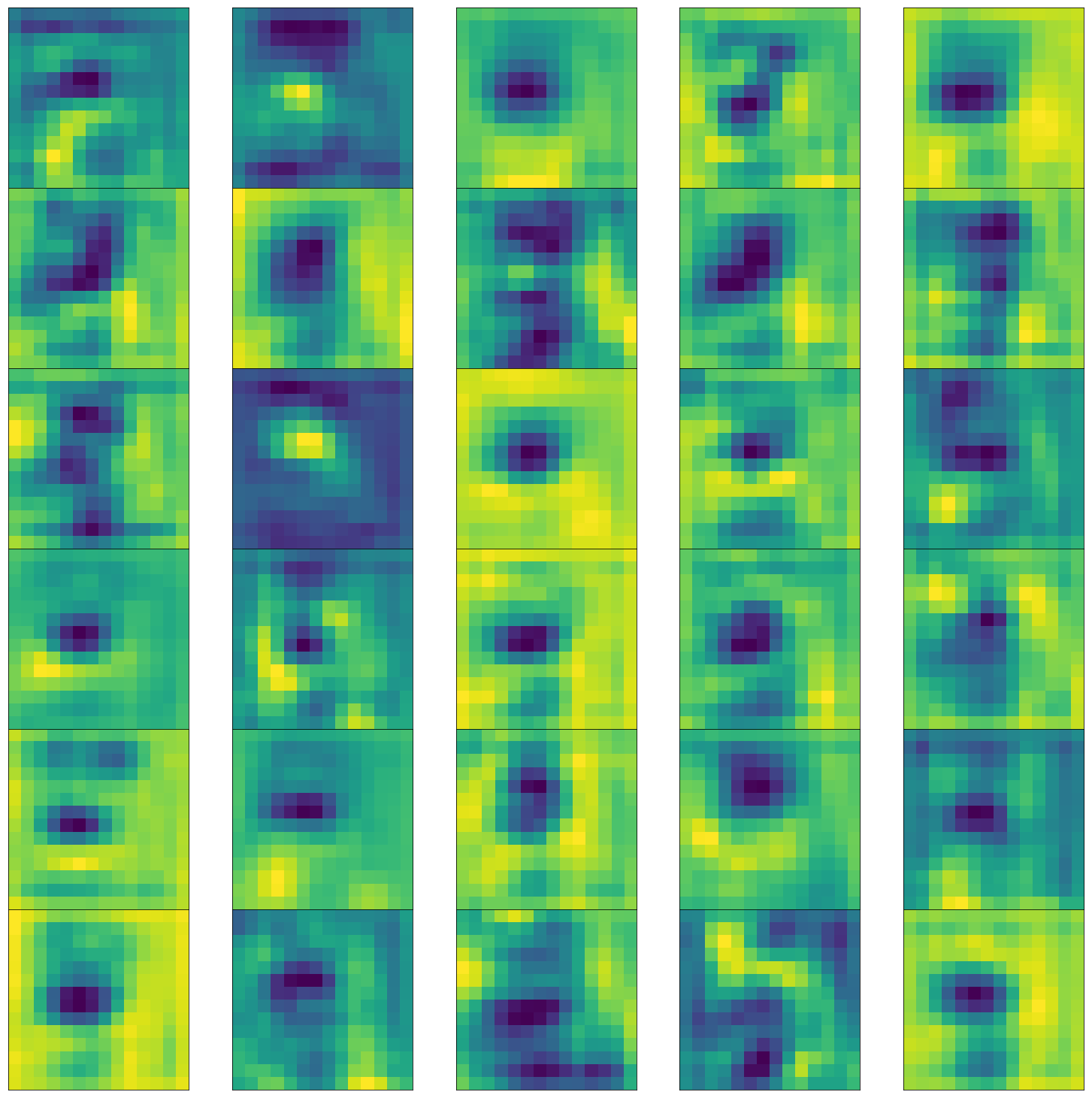
중간 레이어의 가중치 시각화
요약
'IT 도서 리뷰' 카테고리의 다른 글
| PyTorch로 시작하는 딥러닝 - CH7 생성적 신경망 (0) | 2021.11.14 |
|---|---|
| PyTorch로 시작하는 딥러닝 - CH6 시퀀스 데이터와 텍스트 딥러닝 (0) | 2021.11.12 |
| PyTorch로 시작하는 딥러닝 - CH4 머신 러닝 입문 (0) | 2021.11.11 |
| PyTorch로 시작하는 딥러닝 - CH2 신경망 구성 요소 (0) | 2021.10.29 |
| Pytorch로 시작하는 딥러닝 (0) | 2021.10.26 |