

신경망 스타일 트랜스퍼



데이터 로딩
imsize = 512
is_cuda = torch.cuda.is_available()
prep = transforms.Compose([transforms.Resize(imsize),
transforms.ToTensor(),
transforms.Lambda(lambda x: x[torch.LongTensor([2,1,0])]), #turn to BGR
transforms.Normalize(mean=[0.40760392, 0.45795686, 0.48501961], #subtract imagenet mean
std=[1,1,1]),
transforms.Lambda(lambda x: x.mul_(255)),
])
postpa = transforms.Compose([transforms.Lambda(lambda x: x.mul_(1./255)),
transforms.Normalize(mean=[-0.40760392, -0.45795686, -0.48501961], #add imagenet mean
std=[1,1,1]),
transforms.Lambda(lambda x: x[torch.LongTensor([2,1,0])]), #turn to RGB
])
postpb = transforms.Compose([transforms.ToPILImage()])
def postp(tensor): # to clip results in the range [0,1]
t = postpa(tensor)
t[t>1] = 1
t[t<0] = 0
img = postpb(t)
return img
def image_loader(image_name):
image = Image.open(image_name)
image = Variable(prep(image))
# fake batch dimension required to fit network's input dimensions
image = image.unsqueeze(0)
return imagestyle_img = image_loader("Images/vangogh_starry_night.jpg")
content_img = image_loader("Images/amrut1.jpg")opt_img = Variable(content_img.data.clone(),requires_grad=True)
VGG 모델 생성
vgg = vgg19(pretrained=True).features
for param in vgg.parameters():
param.requires_grad = False
콘텐츠 오차
target_layer = dummy_fn(content_img)
noise_layer = dummy_fn(noise_img)
criterion = nn.MSELoss
content_loss = criterion_target_layer, noise_layer)
스타일 오차

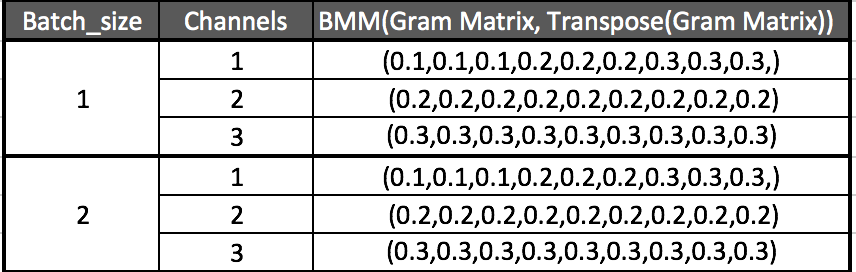
class GramMatrix(nn.Module):
def forward(self,input):
b,c,h,w = input.size()
features = input.view(b,c,h*w)
gram_matrix = torch.bmm(features,features.transpose(1,2))
gram_matrix.div_(h*w)
return gram_matrixclass StyleLoss(nn.Module):
def forward(self,inputs,targets):
out = nn.MSELoss()(GramMatrix()(inputs),targets)
return (out)
VGG 모델 레이어의 오차 추출
class LayerActivations():
features=[]
def __init__(self,model,layer_nums):
self.hooks = []
for layer_num in layer_nums:
self.hooks.append(model[layer_num].register_forward_hook(self.hook_fn))
def hook_fn(self,module,input,output):
self.features.append(output)
def remove(self):
for hook in self.hooks:
hook.remove()def extract_layers(layers,img,model=None):
la = LayerActivations(model,layers)
#Clearing the cache
la.features = []
out = model(img)
la.remove()
return la.features
content_targets = extract_layers(content_layers,content_img,model=vgg)
style_targets = extract_layers(style_layers,style_img,model=vgg)
content_targets = [t.detach() for t in content_targets]
style_targets = [GramMatrix()(t).detach() for t in style_targets]
targets = style_targets + content_targetsstyle_weights = [1e3/n**2 for n in [64,128,256,512,512]]
content_weights = [1e0]
weights = style_weights + content_weights
각 레이어의 오차 함수 만들기
loss_fns = [StyleLoss()] * len(style_layers) + [nn.MSELoss()] * len(content_layers)
옵티마이저 만들기
optimizer = optim.LBFGS([opt_img]);
학습
max_iter = 500
show_iter = 50
optimizer = optim.LBFGS([opt_img]);
n_iter=[0]
while n_iter[0] <= max_iter:
def closure():
optimizer.zero_grad()
out = extract_layers(loss_layers,opt_img,model=vgg)
layer_losses = [weights[a] * loss_fns[a](A, targets[a]) for a,A in enumerate(out)]
loss = sum(layer_losses)
loss.backward()
n_iter[0]+=1
#print loss
if n_iter[0]%show_iter == (show_iter-1):
print('Iteration: %d, loss: %f'%(n_iter[0]+1, loss.data))
return loss
optimizer.step(closure)
생성적 절대 신경망
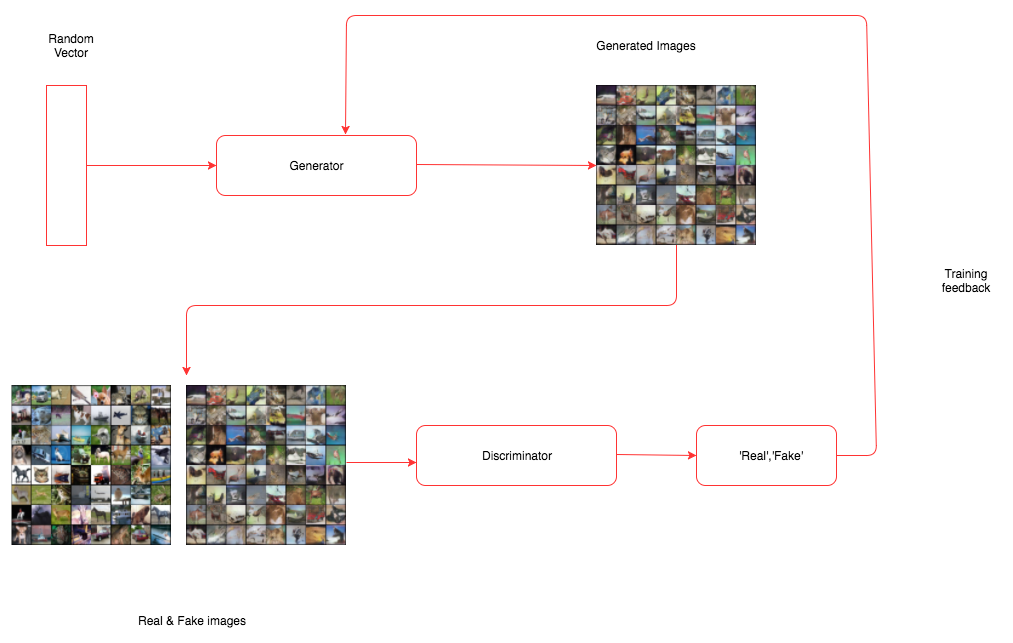
심층 레볼루션 GAN
생성기 네트워크 정의
전치 컨볼루션
배치 정규화
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
생성기 네트워크 정의
class Generator(nn.Module):
def __init__(self):
super(_netG, self).__init__()
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
output = self.main(input)
return output
netG = _netG()
netG.apply(weights_init)
print(netG)def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
판별기 네트워크 정의
class Dicriminator(nn.Module):
def __init__(self):
super(_netD, self).__init__()
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
output = self.main(input)
return output.view(-1, 1).squeeze(1)
netD = _netD()
netD.apply(weights_init)
print(netD)
오차와 옵티마이저 정의
criterion = nn.BCELoss()
# setup optimizer
optimizerD = optim.Adam(netD.parameters(), lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr, betas=(beta1, 0.999))
판별기 네트워크 학습
실제 이미지로 판별기 학습시키기
output = netD(inputv)
errG_real = criterion(output, labelv)
errG_real.backward()
가짜 이미지로 판별기 학습시키기
fake = netG(noisev)
output = netD(fake.detach())
errD_fake = criterion(output, labelv)
errD_fake.backward()
optimizerD.step()
생성기 네트워크 학습
netG.zero_grad()
labelv = Variable(label.fill_(real_label))
output = netD(fake)
errG = criterion(output, labelv)
errG.backward()
optimizerG.step()
전체 네트워크 학습시키기
for epoch in range(niter):
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
# train with real
netD.zero_grad()
real_cpu, _ = data
batch_size = real_cpu.size(0)
if torch.cuda.is_available():
real_cpu = real_cpu.cuda()
input.resize_as_(real_cpu).copy_(real_cpu)
label.resize_(batch_size).fill_(real_label)
inputv = Variable(input)
labelv = Variable(label)
output = netD(inputv)
errD_real = criterion(output, labelv)
errD_real.backward()
D_x = output.data.mean()
# train with fake
noise.resize_(batch_size, nz, 1, 1).normal_(0, 1)
noisev = Variable(noise)
fake = netG(noisev)
labelv = Variable(label.fill_(fake_label))
output = netD(fake.detach())
errD_fake = criterion(output, labelv)
errD_fake.backward()
D_G_z1 = output.data.mean()
errD = errD_real + errD_fake
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
labelv = Variable(label.fill_(real_label)) # fake labels are real for generator cost
output = netD(fake)
errG = criterion(output, labelv)
errG.backward()
D_G_z2 = output.data.mean()
optimizerG.step()
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'
% (epoch, niter, i, len(dataloader),
errD.data.item(), errG.data.item(), D_x, D_G_z1, D_G_z2))
if i % 100 == 0:
vutils.save_image(real_cpu,
'%s/real_samples.png' % outf,
normalize=True)
fake = netG(fixed_noise)
vutils.save_image(fake.data,
'%s/fake_samples_epoch_%03d.png' % (outf, epoch),
normalize=True)
생성 이미지 검토


언어 모델
데이터 준비

TEXT = d.Field(lower=True, batch_first=True,)
train, valid, test = datasets.WikiText2.splits(TEXT,root='data')
배치 처리기 생성
train_iter, valid_iter, test_iter = d.BPTTIterator.splits((train, valid, test), batch_size=batch_size, bptt_len=bptt_len, device=0,repeat=False)
배치
Backpropagation through time
LSTM에 기반을 둔 모델 정의
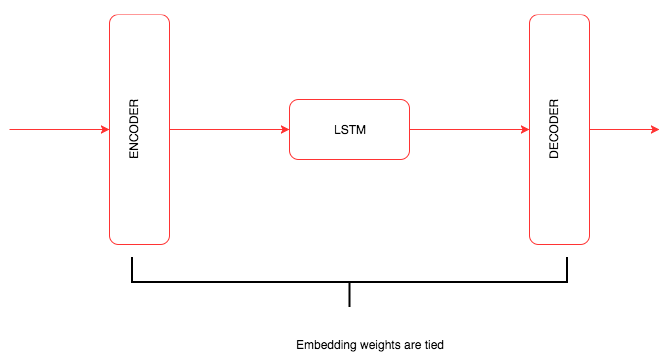
class RNNModel(nn.Module):
def __init__(self,ntoken,ninp,nhid,nlayers,dropout=0.5,tie_weights=False):
super().__init__()
self.drop = nn.Dropout()
self.encoder = nn.Embedding(ntoken,ninp)
self.rnn = nn.LSTM(ninp,nhid,nlayers,dropout=dropout)
self.decoder = nn.Linear(nhid,ntoken)
if tie_weights:
self.decoder.weight = self.encoder.weight
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange,initrange)
self.decoder.bias.data.fill_(0)
self.decoder.weight.data.uniform_(-initrange,initrange)
def forward(self,input,hidden):
emb = self.drop(self.encoder(input))
output,hidden = self.rnn(emb,hidden)
output = self.drop(output)
s = output.size()
decoded = self.decoder(output.view(s[0]*s[1],s[2]))
return decoded.view(s[0],s[1],decoded.size(1)),hidden
def init_hidden(self,bsz):
weight = next(self.parameters()).data
return(Variable(weight.new(self.nlayers,bsz,self.nhid).zero_()),Variable(weight.new(self.nlayers,bsz,self.nhid).zero_()))
학습과 평가 함수 정의
criterion = nn.CrossEntropyLoss()
def trainf():
# Turn on training mode which enables dropout.
lstm.train()
total_loss = 0
start_time = time.time()
hidden = lstm.init_hidden(batch_size)
for i,batch in enumerate(train_iter):
data, targets = batch.text,batch.target.view(-1)
if is_cuda :
data = data.cuda()
targets = targets.cuda()
# Starting each batch, we detach the hidden state from how it was previously produced.
# If we didn't, the model would try backpropagating all the way to start of the dataset.
hidden = repackage_hidden(hidden)
lstm.zero_grad()
output, hidden = lstm(data, hidden)
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
torch.nn.utils.clip_grad_norm(lstm.parameters(), clip)
for p in lstm.parameters():
p.data.add_(-lr, p.grad.data)
total_loss += loss.data
if i % log_interval == 0 and i > 0:
cur_loss = total_loss.item() / log_interval
elapsed = time.time() - start_time
(print('| epoch {:3d} | {:5d}/{:5d} batches | lr {:02.2f} | ms/batch {:5.2f} | loss {:5.2f} | ppl {:8.2f}'.format(epoch, i, len(train_iter), lr,elapsed * 1000 / log_interval, cur_loss, math.exp(cur_loss))))
total_loss = 0
start_time = time.time()def repackage_hidden(h):
"""Wraps hidden states in new Variables, to detach them from their history."""
if type(h) == Tensor:
return h.detach().cuda()
else:
return tuple(repackage_hidden(v) for v in h)def evaluate(data_source):
# Turn on evaluation mode which disables dropout.
lstm.eval()
total_loss = 0
hidden = lstm.init_hidden(batch_size)
for batch in data_source:
data, targets = batch.text,batch.target.view(-1)
output, hidden = lstm(data.cuda(), hidden)
output_flat = output.view(-1, ntokens)
if is_cuda :
targets = targets.cuda()
total_loss += len(data) * criterion(output_flat, targets).data
hidden = repackage_hidden(hidden)
return total_loss.item()/(len(data_source.dataset[0].text)//batch_size)
모델 학습
best_val_loss = None
epochs = 40
for epoch in range(1, epochs+1):
epoch_start_time = time.time()
trainf()
val_loss = evaluate(valid_iter)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if not best_val_loss or val_loss < best_val_loss:
best_val_loss = val_loss
else:
# Anneal the learning rate if no improvement has been seen in the validation dataset.
lr /= 4.0
요약
'IT 도서 리뷰' 카테고리의 다른 글
| [CS 전공지식 노트] CH2 네트워크 (0) | 2023.06.05 |
|---|---|
| [CS 전공지식 노트] CH1 디자인패턴과 프로그래밍 패러다임 (0) | 2023.05.29 |
| PyTorch로 시작하는 딥러닝 - CH6 시퀀스 데이터와 텍스트 딥러닝 (0) | 2021.11.12 |
| PyTorch로 시작하는 딥러닝 - CH5 컴퓨터 비전 딥러닝 (0) | 2021.11.11 |
| PyTorch로 시작하는 딥러닝 - CH4 머신 러닝 입문 (0) | 2021.11.11 |